http://www.mysql.com/why-mysql/white-papers/mysql-high-availability-drbd-configuration-deployment-guide/
http://www.mysql.com/why-mysql/white-papers/#en-22-16
http://www.mysql.com/why-mysql/white-papers/#zh-22-16
http://clusterlabs.org/quickstart-redhat.html
http://download.opensuse.org/repositories/network:/ha-clustering/CentOS_CentOS-6/
http://savannah.nongnu.org/projects/crmsh/
ORACLE 提出了幾個 MySQL HA 建置方案供做參考,如下表:

DRBD 的簡要介紹可參考 維基百科
規劃:
作業系統 CentOS 6.2(基於公司版本統一起見,不過這讓老灰鴨吃足苦頭,CentOS6.4 之後的版本可能會比較好架......)
兩台主機的名稱分別為
host1(10.71.0.207) 及
host2(10.71.0.208)
對外 IP 為 10.71.0.209
gateway:10.71.0.254
子網路遮罩:255.255.255.0
預定 MySQL 資料存放位置 -- /var/lib/mysql_drbd/。
STEP 1.
安裝 2 台 CentOS 6.2 的主機,
1.1 確認兩台主機的網卡名稱一致,在本例中為 eth0
1.2 要存放 MySQL 資料的磁區要先預留,空下來,不做磁區分割。

為了之後的設定檔統一,所以將 LVM 儲區群組改名為一樣,並且留下 1G 的未分割空間,將來放 MySQL 的資料用,這個未分割空間要留在 sda 也行,不過個人認為 LVM 對磁區的調整較彈性。
安裝選項的自訂項目勾選 "高可用性",並全選右方的自訂項目

為了確保兩台主機的設定都是一樣的,建議在 host1 編寫設定檔,寫好之後,再以 scp 指令透過網路複製到 host2,這樣查問題會比較好查。
STEP 2.
[兩台主機]暫時關閉防火牆,因為本文是以架設兩台全新主機,讓環境最單純。
STEP 3.
停止並取消 NetworkManager 服務(注意大小寫)
[兩台主機]service NetworkManager stop
[兩台主機]chkconfig NetworkManager off
變更 SELINUX 的設定為 disabled,理由是 ---- 我不熟 SELINUX... :-P
[root@host1 ~]vi /etc/selinux/config
將 SELINUX=enforcing 改為
SELINUX=disabled
存檔後,複製到 host2
[root@host1 ~]scp /etc/selinux/config host2:/etc/selinux/
STEP 5.
修改 host1 的 /etc/hosts,
[root@host1 ~]vi /etc/hosts
內容如下:
127.0.0.1 localhost localhost.localdomain
::1 localhost localhost.localdomain
10.71.0.207 host1 host1.localdomain
10.71.0.208 host2 host2.localdomain
存檔後,複製到 host2
[root@host1 ~]scp /etc/hosts host2:/etc/
兩台主機皆重新啟動
STEP 6.
因為 CentOS6.x 沒有內建 DRBD 套件,現在的第三方套件也學習 RedHat 官方模式,提供 repository 給使用者,一併解決了相依性問題,而 pkgs.org 是一個提供第三方套件資訊的網站,到 pkgs.org 查詢得知 atrpms.net 有打包好的 DRBD 套件;目前 DRBD 最新版本為 DRBD-8.4.3。
[兩台主機]cd /tmp
[兩台主機]wget http://dl.atrpms.net/el6-i386/atrpms/stable/atrpms-repo-6-6.el6.i686.rpm
安裝
[兩台主機]rpm -Uvh atrpms-repo*rpm
[兩台主機]yum install drbd
STEP 7.
建立 drbd 的磁區:
[兩台主機]lvcreate -l 100%free -n /dev/vg_host/lv_drbd
下指令後,顯示結果
Logical volume "lv_drbd" created
重開機,使磁區分割生效。
要檢視磁區,輸入
lvscan
STEP 8.
先在 host1 編寫 drbd 資源設定檔
更改 /etc/drbd.conf 檔名為 /etc/drbd.conf.bak
[root@host1 ~]mv /etc/drbd.conf /etc/drbd.conf.bak
複製 /etc/drbd.d/global_common.conf 到 /etc/ 且檔名改為 /etc/drbd.conf
更改 /etc/drbd.conf 檔名為 /etc/drbd.conf.bak
[root@host1 ~]mv /etc/drbd.conf /etc/drbd.conf.bak
複製 /etc/drbd.d/global_common.conf 到 /etc/ 且檔名改為 /etc/drbd.conf
[root@host1 ~]cp /etc/drbd.d/global_common.conf /etc/drbd.conf
修改 /etc/drbd.conf 成下述內容:
global
{
usage-count yes;
}
resource clusterdb_res
{
protocol C;
handlers
{
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-
reboot.sh; echo b > /proc/sysrq-trigger; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-
reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.
sh; echo o > /proc/sysrq-trigger ; halt -f";
fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
}
startup
{
degr-wfc-timeout 120; # 2 minutes.
outdated-wfc-timeout 2; # 2 seconds.
}
disk
{
on-io-error detach;
}
net
{
cram-hmac-alg "sha1";
shared-secret "clusterdb";
after-sb-0pri disconnect;
after-sb-1pri disconnect;
after-sb-2pri disconnect;
rr-conflict disconnect;
}
syncer
{
rate 10M;
al-extents 257;
on-no-data-accessible io-error;
}
on host1 # 注意這個名字要與下 uname –n 指令所得到的結果一致
{
device /dev/drbd0;
disk /dev/vg_host/lv_drbd;
address 10.71.0.207:7788;
flexible-meta-disk internal;
}
on host2 # 注意這個名字要與下 uname –n 指令所得到的結果一致
{
device /dev/drbd0;
disk /dev/vg_host/lv_drbd;
address 10.71.0.208:7788;
meta-disk internal;
}
}
handlers
{
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-
reboot.sh; echo b > /proc/sysrq-trigger; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-
reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.
sh; echo o > /proc/sysrq-trigger ; halt -f";
fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
}
startup
{
degr-wfc-timeout 120; # 2 minutes.
outdated-wfc-timeout 2; # 2 seconds.
}
disk
{
on-io-error detach;
}
net
{
cram-hmac-alg "sha1";
shared-secret "clusterdb";
after-sb-0pri disconnect;
after-sb-1pri disconnect;
after-sb-2pri disconnect;
rr-conflict disconnect;
}
syncer
{
rate 10M;
al-extents 257;
on-no-data-accessible io-error;
}
on host1 # 注意這個名字要與下 uname –n 指令所得到的結果一致
{
device /dev/drbd0;
disk /dev/vg_host/lv_drbd;
address 10.71.0.207:7788;
flexible-meta-disk internal;
}
on host2 # 注意這個名字要與下 uname –n 指令所得到的結果一致
{
device /dev/drbd0;
disk /dev/vg_host/lv_drbd;
address 10.71.0.208:7788;
meta-disk internal;
}
}
再以 scp 透過網路 drbd.conf 複製到 host2
[root@host1 ~]scp /etc/drbd.conf host2:/etc/
[兩台主機]drbdadm create-md clusterdb_res
啟動 DRBD 服務
[兩台主機]service drbd start
[任一台主機] service drbd status
會看到畫面如下:

指定 host1 為正式機
[root@host1 ~]drbdadm -- --overwrite-data-of-peer primary all
若這時立馬下指令
[root@host1 ~]service drbd status
就會看到如下畫面:

表示 host1(正式機)、host2(備機) 正在同步中
格式化正式機
[root@host1 ~]mkfs -t ext4 /dev/drbd0
STEP 9.
[兩台主機]yum install mysql-server mysql
STEP 10.
變更目錄&目錄權限:
[兩台主機 ~]mkdir /var/lib/mysql_drbd
[兩台主機 ~]chown mysql /var/lib/mysql_drbd
[兩台主機 ~]chgrp mysql /var/lib/mysql_drbd
[兩台主機 ~]chown mysql /var/lib/mysql
[兩台主機 ~]chgrp mysql /var/lib/mysql
STEP 11.
在 host1 mount /dev/drbd0,並建立 MySQL 設定檔
[root@host1 ~]mount /dev/drbd0 /var/lib/mysql_drbd
[root@host1 ~]mkdir /var/lib/mysql_drbd/data
[root@host1 ~]cp /usr/share/mysql/my-small.cnf /var/lib/mysql_drbd/my.cnf
修改 /var/lib/mysql_drbd/my.cnf,
在 [mysqld] 這個區塊加入 datadir 位置,如下:
[mysqld]
datadir = /var/lib/mysql_drbd/data
socket = /var/lib/mysql/mysql.sock
pid = /var/lib/mysql/mysql.pid
STEP 12.
初始化 MySQL database
[root@host1 ~]mysql_install_db --no-defaults --datadir=/var/lib/mysql_drbd/data --user=mysql

初始化 MySQL database 後,千萬不要自行啟動 mysqld!!
[root@host1 ~]cd /var/lib/mysql_drbd
[root@host1 ~]chmod -R uog+rw *
[root@host1 ~]chown mysql my.cnf
[root@host1 ~]chmod og-w my.cnf
[root@host1 ~]chmod 644 my.cnf
[root@host1 ~]chown -R mysql data
umount 磁區
[root@host1 ~]umount /var/lib/mysql_drbd
將正式機角色轉換回備機狀態
[root@host1 ~]drbdadm secondary clusterdb_res
在這個範例中,因為我們只有設定一個 DRBD 資源,也就是 clusterdb_res,所以上述的指令可以偷懶,如下:
[root@host1 ~]drbdadm secondary all
至此,MySQL 的部份設定完畢
STEP 13.
兩台主機 安裝/更新 pacemaker
檢查兩台主機是否已安裝 pacemaker,如果您跟我一樣在全新安裝 Linux 時就已勾選 "高可用性",那麼這幾個套件應都已經裝了。
如果您也是採用 CentOS6.2 且已經安裝了上述套件,就只需要將 pacemaker 更新即可。
[兩台主機]yum update pacemaker
STEP 14.
在 CentOS 6.2 時,crm 這個套件是內含在 pacemaker 內的,之後就成為獨立套件 -- crmsh。
在 STEP 13 我們更新了 pacemaker(一定要更新),因此我們需要再另外下載安裝 crmsh。(如果您是 CentOS6.4,您也需要安裝 crmsh)
檢查兩台主機是否已安裝 pacemaker,如果您跟我一樣在全新安裝 Linux 時就已勾選 "高可用性",那麼這幾個套件應都已經裝了。
如果您也是採用 CentOS6.2 且已經安裝了上述套件,就只需要將 pacemaker 更新即可。
[兩台主機]yum update pacemaker
STEP 14.
在 CentOS 6.2 時,crm 這個套件是內含在 pacemaker 內的,之後就成為獨立套件 -- crmsh。
在 STEP 13 我們更新了 pacemaker(一定要更新),因此我們需要再另外下載安裝 crmsh。(如果您是 CentOS6.4,您也需要安裝 crmsh)
[兩台主機]wget -P /etc/yum.repos.d/ http://download.opensuse.org/repositories/network:/ha-clustering/CentOS_CentOS-6/network:ha-clustering.repo
[兩台主機]yum install crmsh
[兩台主機]yum install crmsh
STEP 15.
複製並修改 corosync 的設定檔
複製並修改 corosync 的設定檔
[root@host1 ~]cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
[root@host1 ~]vi /etc/corosync/corosync.conf
修改為如下內容:
totem
{
version: 2
secauth: off
threads: 0
interface
{
ringnumber: 0
bindnetaddr: 10.71.0.0 # 注意前 3 個數字與 ip 同網段,第 4 個數字為 0
mcastaddr: 226.99.1.1
mcastport: 5405
ttl: 1
}
}
......
......
建立 pcmk
vi /etc/corosync/service.d/pcmk
內容如下:
service
{
#Load the Pacemaker Cluster Resource Manager
name: pacemaker
ver: 1
}
以指令方式建立 /etc/cluster/cluster.conf:
[root@host1 ~]ccs -f /etc/cluster/cluster.conf --createcluster pacemaker1
[root@host1 ~]ccs -f /etc/cluster/cluster.conf --addnode host1
[root@host1 ~]ccs -f /etc/cluster/cluster.conf --addnode host2
[root@host1 ~]ccs -f /etc/cluster/cluster.conf --addfencedev pcmk agent=fence_pcmk
[root@host1 ~]ccs -f /etc/cluster/cluster.conf --addmethod pcmk-redirect host1
[root@host1 ~]ccs -f /etc/cluster/cluster.conf --addmethod pcmk-redirect host2
[root@host1 ~]ccs -f /etc/cluster/cluster.conf --addfenceinst pcmk host1 pcmk-redirect port=host1
[root@host1 ~]ccs -f /etc/cluster/cluster.conf --addfenceinst pcmk host2 pcmk-redirect port=host2
生成的 cluster.conf 是一個 xml 檔
複製前述 3 個檔案至 host2:
[root@host1 ~]scp /etc/corosync/corosync.conf host2:/etc/corosync/
[root@host1 ~]scp /etc/corosync/service.d/pcmk host2:/etc/corosync/service.d/
[root@host1 ~]scp /etc/cluster/cluster.conf host2:/etc/cluster/
啟動 pacemaker
觀察執行結果, -1 是數字
[兩台主機]crm_mon -1
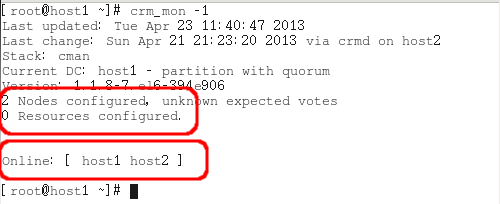
在 HA 把每項要監控、接管的服務/程式稱為 resource,所以在上圖可以看到 2 Nodes configured(已設定 2 節點),0 Resources configured(因為我們還沒設定)。
STEP 16.
在本例中,我們要監控的有檔案系統,兩台主機對外共同的 IP、和 MySQL,接下來就開始設定
[root@host1 ~]crm configure property no-quorum-policy=ignore
[root@host1 ~]crm configure rsc_defaults resource-stickiness=100
[root@host1 ~]crm configure property stonith-enabled=false
停止 DRBD
[root@host1 ~]service drbd stop
建立 crm 設定
[root@host1 ~]crm configure
這時會進入 crm 的編輯模式
crm(live)configure# primitive p_drbd_mysql ocf:linbit:drbd params
drbd_resource="clusterdb_res" op monitor interval="15s"
crm(live)configure# ms ms_drbd_mysql p_drbd_mysql meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
crm(live)configure# primitive p_fs_mysql ocf:heartbeat:Filesystem params device="/dev/drbd0" directory="/var/lib/mysql_drbd" fstype="ext4"
下面這道指令的 ip 是對外 ip,nic 是網卡名稱
crm(live)configure# primitive p_ip_mysql ocf:heartbeat:IPaddr2 params ip="10.71.0.209" cidr_netmask="24" nic="eth0"
下面這道指令很關鍵,先另外開個終端機視窗,查出 mysqld 所在目錄,以我的主機為例,我的 mysqld 在 /usr/libexec/mysqld,其餘如:config、datadir、pid、socket 等都在前面提過
crm(live)configure# primitive p_mysql ocf:heartbeat:mysql params binary="/usr/libexec/mysqld" config="/var/lib/mysql_drbd/my.cnf" datadir="/var/lib/mysql_drbd/data" pid="/var/lib/mysql/mysql.pid" socket="/var/lib/mysql/mysql.sock" user="mysql" group="mysql" additional_parameters="--bind-address=10.71.0.209 --user=mysql" op start timeout=120s op stop timeout=120s op monitor interval=20s timeout=30s
crm(live)configure# group g_mysql p_fs_mysql p_ip_mysql p_mysql
crm(live)configure# colocation c_mysql_on_drbd inf: g_mysql ms_drbd_mysql:Master
crm(live)configure# order o_drbd_before_mysql inf: ms_drbd_mysql:promote g_mysql:start
儲存設定
crm(live)configure# commit
離開
crm(live)configure# exit
所做的設定會立即生效,不需重新啟動 pacemaker 這個 service,結果如下:

如果您跑出來的結果和上圖不同,有可能是某些地方輸入錯誤,可透過下述指令檢視修正:
[root@host1 ~]crm configure edit
如果跑出來的結果如上圖,那再看一個:
[root@host1 ~]service drbd status
則會看到 pacemaker 啟動了剛剛在前面被我們停下來的 DRBD。
因為在 crm configure 階段我們已改變了 mysqld 的啟動方式,所以不要以 service mysqld status 指令去檢查 mysqld 是否啟動成功,因為您會看到 mysqld 已停止 的回應。
題外話:
瞄一下 /usr/lib/ocf/resource.d/heartbeat/ 這個目錄,放著許多 server 套件的 script,我猜...這應該就是 pacemaker 目前支援的 service 吧...
STEP 17.
建立驗證資料庫
[root@host1 ~]mysql -u root -e "GRANT ALL ON *.* to 'root'@'%' "
[root@host1 ~]mysql -h 10.71.0.209 -P3306 -u root
mysql> CREATE DATABASE clusterdb; USE clusterdb;
顯示回應 Database changed
mysql> CREATE TABLE simples (id INT NOT NULL PRIMARY KEY);
mysql> INSERT INTO simples VALUES (1),(2),(3),(4);
mysql> exit
STEP 18.
建立網路斷線時的機制
[root@host1 ~]crm configure
crm(live)configure# primitive p_ping ocf:pacemaker:ping params name="ping" multiplier="1000" host_list="10.71.0.254" op monitor interval="15s" timeout="60s" start timeout="60s"
crm(live)configure# clone cl_ping p_ping meta interleave="true"
crm(live)configure# location l_drbd_master_on_ping ms_drbd_mysql rule $role="Master" -inf: not_defined ping or ping number:lte 0
crm(live)configure# commit
crm(live)configure# exit

STEP 19.
設定開機要啟動的 service
[兩台主機] chkconfig drbd off
[兩台主機] chkconfig mysqld off
[兩台主機] chkconfig pacemaker on
重新開機,從第 3 台主機來試撈資料(第 3 台主機需安裝 MySQL client)
[root@host3 ~]mysql -h 10.71.0.209 -P3306 -u root -e 'SELECT * FROM clusterdb.simples;'
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 4 |
+----+
STEP 20.
指定 host1 當正式機
[root@host1 ~]crm configure edit
找到
location cli-prefer-g_mysql g_mysql rule $id="cli-prefer-rule-g_mysql" inf: #uname eq host1 and #uname eq host2
確認先 host1 在前,host2 在後
STEP 21.
將 crm 設定複製到 host2
[root@host1 ~]crm resource migrate g_mysql host2
(這個動作只需在一開始建置,host2 還沒有設定時,做一次就好了,此後,只要 host1 一儲存設定後,host2 就會跟著更新了)
MySQL HA 環境建置完成!!
狀況模擬
試著拔除 host1 的網路線,大約 5 秒後 host2 就備援上來成為正式機了,不過您的公司若是 24hr 運作,則此 HA 方案可能不太適合,因為當 host1 修復後,有可能不能無痕銜接 -- 因為兩台主機內的資料差異度太大,造成所謂的 腦裂(split-brain);
host2 必需將資料備份出來
--> 下線暫停運作
--> 然後將自 host2 接手後的異動資料倒給 host1
--> 再回復 host1 為正式機,而 host2 為備機的關係。
接下來我想做的是:如果在出狀況時,備機接手成為正式機後,可以通知我,如此我才知道要去修復原本的正式機;可能還要繼續摸索如何結合 postfix 吧...
順道提一下可能會遇到的狀況與處置:
當主機狀態都是 StandAlone 時,嘗試連上線的指令
[root]# drbdadm connect clusterdb_res
當兩台主機都是 Secondary,要令某一台成為 Primary
[root]# drbdadm primary all
(其實 all 一字應鍵入 clusterdb_res,也就是設定的 resource 名稱,但因我們只有一個 resource,所以就偷懶...)
當兩台主機狀態都是 StandAlone 時,
或第 1 台是 StandAlone,第 2 台是 WFConnection 時,嘗試 connect 仍無法連上,
可能就發生了所謂的腦裂(split-brain),表示兩台主機的資料差異太大,要當 secondary 的主機就要捨棄自己的資料,重新向 Primary 索取
先讓 2 台主機都成 StandAlone 狀態
[root]# drbdadm disconnect clusterdb_res
然後令第 2 台連線,並捨棄自己的資料
[root]# drbdadm secondary clusterdb_res
[root]# drbdadm connect --discard-my-data clusterdb_res
另一方面,也令第 1 台連線
這時兩台主機就會開始重新將資料同步(就是將第 1 台的資料倒進第 2 台)
同步完,下
[root]# service drbd status
就會看到第 1 台是 primary,而第 2 台是 Secondary

沒有留言:
張貼留言